Как разделить текст по ячейкам формула в Excel
Часто приходится оптимизировать структуру данных после импорта в Excel. Некоторые разные значения попадают в одну и туже ячейку образуя целую строку как одно значение. Возникает вопрос: как разбить строку на ячейки в Excel. Программа располагает разными поисковыми функциями: одни ищут по ячейках другие ищут по содержимому ячеек. Ведь выполнять поиск по текстовой строке, которая содержится в ячейке ¬– это также распространенная потребность пользователей Excel. Их мы и будем использовать для разделения строк.
Как разделить текст на две ячейки Excel
Допустим на лист Excel были импортированные данные из другой программы. Из-за несовместимости структуры данных при импорте некоторые значение из разных категорий были внесены в одну ячейку. Необходимо из этой ячейки отделить целые числовые значения. Пример таких неправильно импортированных данных отображен ниже на рисунке:

Сначала определим закономерность, по которой можно определить, что данные из разных категорий, несмотря на то, что они находятся в одной и той же строке. В нашем случае нас интересуют только числа, которые находятся вне квадратных скобок. Каким способом можно быстро выбрать из строк целые числа и поместить их в отдельные ячейки? Эффективным решением является гибкая формула основана на текстовых функциях.
В ячейку B3 введите следующую формулу:
Теперь скопируйте эту формулу вдоль целого столбца:
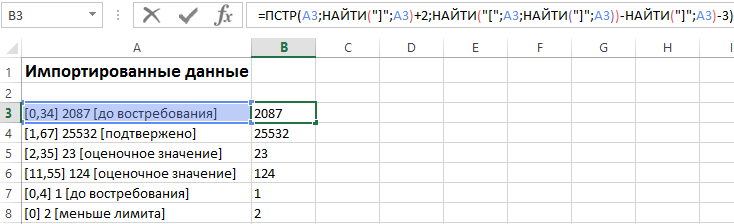
Выборка чисел из строк в отдельные ячейки.
Описание формулы для разделения текста по ячейкам:
Функция ПСТР возвращает текстовое значение содержащие определенное количество символов в строке. Аргументы функции:
- Первый аргумент – это ссылка на ячейку с исходным текстом.
- Второй аргумент – это позиция первого символа, с которого должна начинаться разделенная строка.
- Последний аргумент – это количество символов, которое должна содержать разделенная строка.
С первым аргументом ПСТР все понятно – это ссылка на ячейку A3. Второй аргумент мы вычисляем с помощью функции НАЙТИ("]";A3)+2. Она возвращает очередной номер символа первой закрывающейся квадратной скобки в строке. И к этому номеру мы добавляем еще число 2, так как нам нужен номер символа после пробела за квадратной скобкой. В последнем аргументе функция вычисляет какое количество символов будет содержать разделенная строка после разделения, учитывая положение квадратной скобки.
Обратите внимание! Что в нашем примере все исходные и разделенные строки имеют разную длину и разное количество символов. Именно поэтому мы называли такую формулу – гибкой, в начале статьи. Она подходит для любых условий при решении подобного рода задач. Гибкость придает ей сложная комбинация из функций НАЙТИ. Пользователю формулы достаточно определить закономерность и указать их в параметрах функций: будут это квадратные скобки либо другие разделительные знаки. Например, это могут быть пробелы если нужно разделить строку на слова и т.п.
В данном примере функция НАЙТИ во втором аргументе определяет положение относительно первой закрывающейся скобки. А в третьем аргументе эта же функция вычисляет положение нужного нам текста в строке относительно второй открывающийся квадратной скобки. Вычисление в третьем аргументе более сложное и оно подразумевает вычитание одной большей длинны текста от меньшей. А чтобы учитывать еще 2 пробела следует вычитать число 3. В результате чего получаем правильное количество символов в разделенной строке. С помощью такой гибкой формулы можно делать выборку разной длинны разделенного текста из разных длинны исходных строк.
Красивые шаблоны визуализации данных для создания отчетов в Excel
Скачать Шаблоны